
一、为什么机器人行业需要”通用大脑”?
1.1 当下的困境
机器人行业有一个根本性的难题:“大脑”和”躯体”严重割裂。
你想让一个机器人去搬箱子,为工业机械臂开发的算法,无法直接用在家庭服务机器人上;为轮式机器人训练的数据,四足机器人也用不了。每换一种形态,几乎都要从零开始。这导致了两个严重后果:
开发成本高昂
从头训练一个机器人的控制系统,需要海量的数据、算力和时间。据行业估算,一个能实际商用的机器人,从立项到落地通常需要3-5年,耗资数千万甚至上亿。这让很多有创意的团队望而却步。
落地周期漫长
好不容易开发出来的机器人,因为场景变化或用户需求调整,往往需要二次开发。比如工厂里的机械臂,想改造成能适应柔性生产线的版本,又是一轮漫长的调试。
1.2 高德的解题思路
高德提出的方案很直接:既然问题出在”不通用”上,那就做一个通用的。
ABot-M0模型通过一套统一的架构和数据处理管线,将不同形态机器人的数据、坐标系和控制信号”翻译”成同一种语言。就像USB接口统一了各种设备的连接方式一样,ABot-M0要统一各种机器人的”大脑”。
这套方案的核心价值在于:效率的飞跃。基于这个开源模型,开发者进行二次开发的预训练周期可以缩短60%以上。过去需要庞大团队耗时数年才能启动的项目,现在一个小团队可能在几个月内就能看到雏形。
二、ABot-M0的技术原理
2.1 统一架构的三大支柱
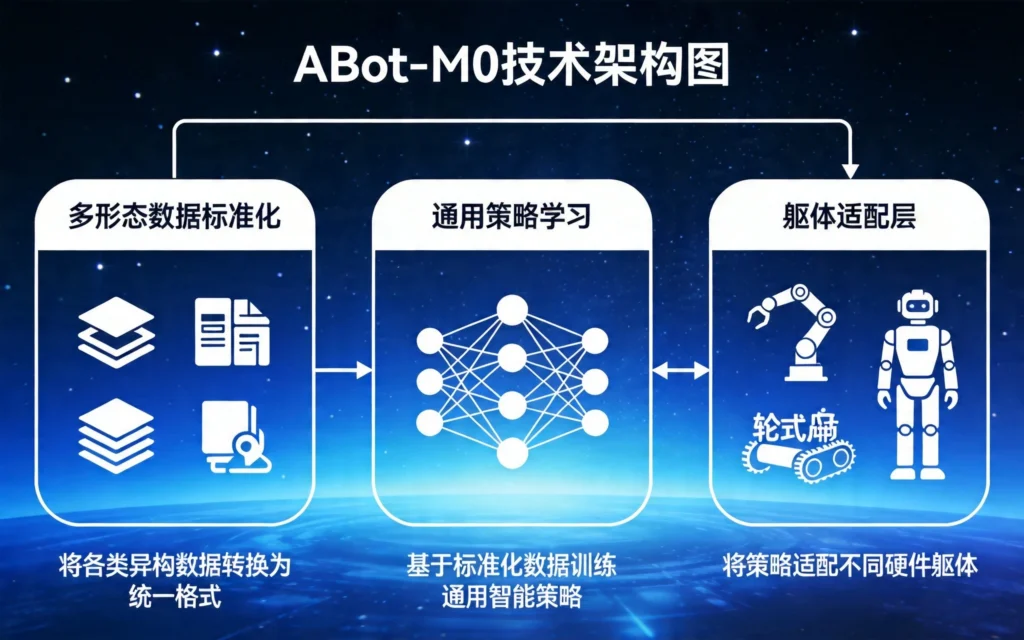
ABot-M0的技术架构包含三个核心部分:
第一部分:多形态数据标准化
传统方法中,单臂机械臂、双臂机器人、轮式移动机器人、四足机器人的数据格式完全不同,无法直接复用。ABot-M0构建了一套统一的数据表示方法,将不同形态机器人的感知数据、运动数据、控制信号都映射到同一个语义空间中。
打个比方,这就像是建立了机器人世界的”世界语”。不管是哪个国家的人(哪种形态的机器人),只要学会了这门语言,就能互相交流。
第二部分:通用策略学习
在标准化数据的基础上,ABot-M0训练了一个通用的策略网络。这个网络不针对特定任务,而是学习”如何学习操作”——也就是迁移学习和泛化能力。当遇到新任务时,网络能快速适应,而不是从零开始。
这个思路有点类似于人类的”举一反三”能力。一个会骑自行车的人,学习骑摩托车会很快,因为很多平衡感和操控逻辑是相通的。ABot-M0就是要让机器人具备这种能力。
第三部分:躯体适配层
最后,ABot-M0保留了针对特定躯体的适配层。这部分可以根据目标机器人的具体硬件参数进行微调,确保通用策略能精准落地到具体形态上。
适配层的设计很巧妙:它是”轻量级”的,不需要从头训练,只需要少量数据和短时间微调就行。这就像一个通用翻译官学会了世界语后,去一个新地方只需要适应一下当地口音,而不需要重新学语言。
2.2 Libero-Plus测试:80.5%的任务成功率
技术好不好,要看实际测试结果。在Libero-Plus等权威测试中,ABot-M0取得了80.5%的任务成功率,比前代标杆提升了近30个百分点。
Libero-Plus是一个综合性的机器人操作基准测试,涵盖了抓取、放置、装配、导航等多种任务类型。80.5%的成功率意味着,在大多数日常操作场景中,这个模型都能可靠地完成任务。
2.3 UniACT数据集:行业最大的”驾驶培训学校”
支撑ABot-M0高性能的,还有一个关键资源:UniACT数据集。
这个数据集整合了超过600万条真实机器人的操作轨迹。高德把它比喻为”行业最大的驾驶培训学校”——就像驾校积累了大量老司机的驾驶录像,新手司机通过学习这些数据,可以快速掌握各种场景下的驾驶技能。
数据集中包含了不同形态机器人(单臂、双臂、轮式、四足)在各种场景(工厂、家庭、仓库、户外)的操作数据。这些数据的多样性,是ABot-M0能够泛化的关键。
三、”老司机思维”的动作流形学习
3.1 传统算法的困境
传统的机器人动作规划算法,有一个根本性的效率问题:试错成本太高。
想象一下,新手学开车时会怎么操作?先想”方向盘打多少度”,不对再调整,再不对再调整,反反复复。这个过程浪费了大量时间和计算资源。
传统机器人算法就是这样工作的:生成一个动作,执行,发现偏差,修正,再执行,再修正……在真实的物理世界中,这种试错过程既耗时又可能造成损坏。
3.2 AML算法的创新
高德提出了一个更聪明的方案:动作流形学习(AML – Action Manifold Learning)。
这个算法的核心思路是:让机器人学会”预判”,而不是”试错”。
具体来说,AML算法会学习一个”动作流形”——这是一个描述各种可行动作连续空间的几何结构。简单理解,就是机器人在这个空间里”看到”动作之间的内在联系,而不是孤立的动作点。
当遇到新任务时,AML算法能直接规划出一条从起点到终点的平滑、可行的动作轨迹,而不是反复试错。这将策略稳定性提升了40%以上。
3.3 双流感知架构
ABot-M0还采用了一个创新的”双流感知架构”:
- 语义流:理解”把桌上的红色杯子拿过来”这样的高级语义指令
- 空间流:精准感知杯子在三维空间中的具体位置和姿态
两个流的信息最终融合,让机器人既知道”要做什么”,又知道”怎么做”。这解决了以往AI系统中”语义理解”和”空间感知”割裂的问题。
四、应用场景与产业影响
4.1 对开发者的价值
对于机器人开发者来说,ABot-M0开源意味着什么?
降低门槛
过去只有大公司才能做的机器人项目,现在小团队也能玩了。你不需要从零搭建基础模型,直接基于ABot-M0做应用开发就行。
缩短周期
预训练周期缩短60%,意味着原来需要1年的工作,现在4个月就能完成。这对于需要快速验证市场的创业公司来说,是巨大的竞争优势。
提升性能
直接使用经过验证的模型架构比自己从头训练的效果更好。80.5%的任务成功率,是很多团队自己训练达不到的。
4.2 潜在应用场景
基于ABot-M0的能力,以下几个场景可能率先落地:
工业柔性制造
工厂生产线需要频繁调整产品类型。基于ABot-M0,可以快速让机器人适应新产品,大幅降低换产成本。
服务机器人
酒店、商场、医院等场景的服务机器人,需要应对各种非标准化的任务。通用大脑让它们能更快学习新技能。
特种作业
危险环境下的机器人作业(如高压电维修、核电站巡检),数据采集困难,ABot-M0的泛化能力尤其有价值。
物流仓储
分拣、搬运、盘点等重复性任务,ABot-M0可以统一控制不同类型的机器人,提高整体效率。
4.3 生态影响
高德开源ABot-M0,不仅仅是发布一个模型,而是在建立一种行业标准。
就像安卓系统通过开源建立了移动生态一样,ABot-M0通过统一架构,正在吸引开发者围绕它构建工具链、模型库、应用案例。生态一旦形成,后来的参与者会自然选择加入,形成正向循环。
五、与国际同行的对比
5.1 全球竞争格局
具身智能是2026年AI领域最热门的方向之一,全球各大科技公司都在布局:
| 公司/机构 | 代表模型 | 特点 |
|---|---|---|
| 谷歌DeepMind | RT系列 | 视频学习能力突出 |
| Figure | Figure 01 | 人形机器人整机研发 |
| 特斯拉 | Optimus | 量产优势明显 |
| 智元机器人 | Go1 | 国内头部,人形方向 |
| 高德 | ABot-M0 | 统一架构,开源生态 |
5.2 高德的差异化优势
相比其他玩家,高德的策略有明显差异:
开源优先
高德选择开源核心模型,这是很大胆的决定。短期看,让竞争对手也能用;但长期看,能快速建立行业标准,吸引开发者,形成生态护城河。
架构统一
大多数竞争对手的做法是针对特定形态开发专用模型(如专用于人形机器人的、专用于机械臂的),高德从一开始就瞄准了”大一统”,这个路线难度更高,但成功后价值也更大。
导航基因
高德做具身智能不是凭空起高楼。它过去十几年积累的”空间智能”能力——包括高精度地图、实时定位、路径规划等——可以自然迁移到机器人的感知和决策中。这是其他公司不具备的优势。
六、普通用户什么时候能用上?
6.1 当前状态
ABot-M0目前已经开源,开发者可以在GitHub上获取模型权重和技术文档。但对于普通消费者来说,真正用到基于这项技术的产品,还需要一段时间。
6.2 时间预期
根据行业经验,技术从开源到成熟产品落地,通常需要1-2年。预计:
- 2026年下半年:基于ABot-M0的开发者工具链成熟
- 2027年上半年:第一批B端商业应用落地(工厂、医院等)
- 2027年下半年-2028年:C端消费级产品可能出现
当然,这只是基于历史经验的推测,实际进度取决于技术成熟度和市场接受度。
6.3 个人如何参与?
如果你对具身智能感兴趣,有几种参与方式:
开发者路线
直接使用开源代码开发应用,高德提供了详细的文档和示例。
学习路线
关注高德的技术博客和论文,了解具身智能的最新进展。
投资路线
关注机器人产业链上下游的公司,具身智能的发展会带动整个产业链的机会。
七、总结
高德开源ABot-M0,是2026年AI领域的一个重要事件。它提出的”通用大脑+专用躯体”范式,有望解决机器人行业长期存在的碎片化问题。如果这个方向被验证成功,将大大加速机器人技术的落地进程。
对于开发者来说,这是难得的机会——一个已经验证可行的基础模型,降低了进入门槛,缩短了开发周期。
对于整个行业来说,ABot-M0可能成为一个转折点。它让机器人从”定制开发”走向”平台开发”,从”封闭生态”走向”开放生态”。
接下来就看社区的反馈和生态的发展了。作为一个AI爱好者,我会持续关注这个项目的进展,也期待看到更多基于ABot-M0的创新应用出现。











