一、为什么你需要掌握AI长文本处理
先问大家一个问题:你有多久没有完整读完一本书了?
不是不想读,是真的没时间。
作为一个每天要处理大量信息的人,我深刻理解这种痛苦:
- 学生党:要看大量论文、教材、文献综述
- 职场人:要看合同、报告、邮件、行业资料
- 研究者:要看最新的学术论文、行业报告
传统阅读方式效率太低。但AI工具的出现,正在改变这一切。
现在的AI助手,比如Kimi、ChatGPT、Claude,都已经支持处理超长文本。理论上,一本几十万字的书丢给AI,它能帮你快速理解核心内容。
但问题是:很多人用不好这些工具。
要么不知道怎么把文档正确喂给AI,要么提问方式不对,导致AI的回答不痛不痒。
这篇文章,就是来帮你解决这些问题的。
二、主流AI长文本工具对比
2.1 Kimi:国产之光
Kimi是月之暗面推出的AI助手,最大的特点是支持超长上下文。
核心参数:
- 上下文窗口:200万Token(最新版本)
- 支持文件格式:PDF、Word、TXT、Markdown、Excel、PPT等
- 价格:免费使用(有一定额度限制)
优势:
- 中文理解能力强
- 支持多种文档格式
- 界面简洁,上手容易
- 免费额度对普通用户够用
适用场景:
- 中文文档处理
- 论文文献分析
- 长篇小说阅读
- 合同条款审查
2.2 Claude:长文本处理的强者
Claude是Anthropic推出的AI助手,在长文本处理上有明显优势。
核心参数:
- 上下文窗口:20万Token(Claude 3.7版本)
- 支持文件格式:PDF、TXT、CSV等
- 价格:免费版有限制,Pro版更强大
优势:
- 分析能力强,理解深度好
- 回答更加详细和有逻辑
- 擅长复杂问题的拆解
- 安全性和稳定性好
适用场景:
- 深度分析报告
- 复杂技术文档
- 代码理解
- 创意写作
2.3 ChatGPT:全能型选手
ChatGPT的上下文窗口虽然不是最大的,但综合能力强。
核心参数:
- 上下文窗口:200万Token(GPT-5版本)
- 支持文件格式:PDF、图片、Excel、Word等
- 价格:Plus会员约20美元/月
优势:
- 生态完善,插件丰富
- 可以结合联网搜索
- 支持多模态处理
- 代码能力强
适用场景:
- 需要结合最新信息的分析
- 多模态文档处理
- 综合性文档理解
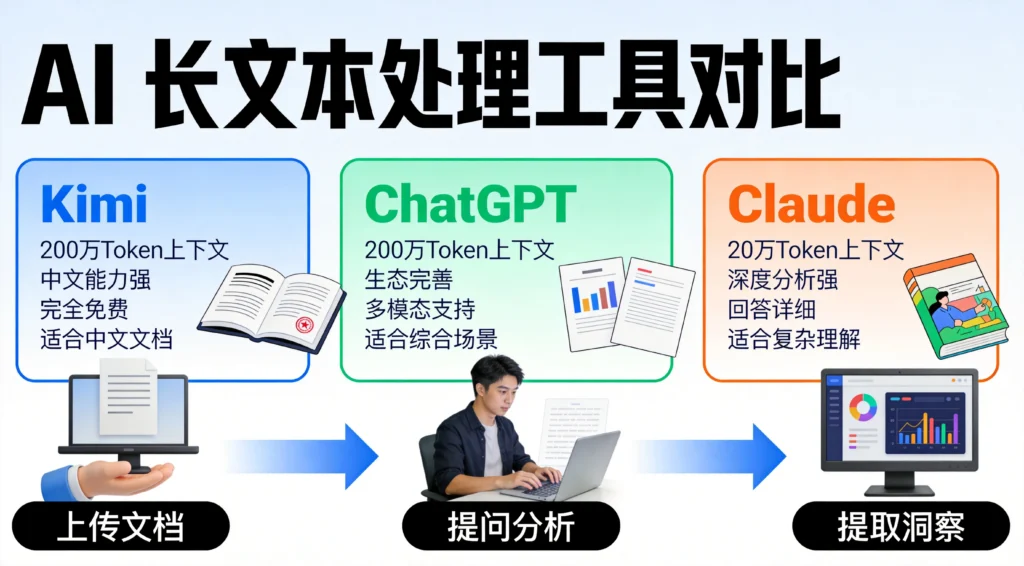
2.4 对比总结
| 工具 | 上下文长度 | 中文能力 | 免费程度 | 适用场景 |
|---|---|---|---|---|
| Kimi | 200万Token | 强 | 完全免费 | 中文文档、快速处理 |
| Claude | 20万Token | 中等 | 部分免费 | 深度分析、复杂理解 |
| ChatGPT | 200万Token | 中等 | 付费更好用 | 综合场景、多模态 |
三、AI长文本处理基础技巧
3.1 如何正确给AI”喂”文档
这是最基础但很多人会出错的地方。
正确方式1:直接复制粘贴
适用于较短的文本(几千字以内)。
直接复制文档内容,粘贴到AI对话框中。
注意:不需要保留原文格式,粘贴纯文本即可。保留格式反而可能干扰AI理解。
正确方式2:上传文档
适用于较长的文档。
主流AI工具都支持上传文件:
- Kimi:支持拖拽上传,点击回形针图标上传
- Claude:点击回形针图标上传
- ChatGPT:点击回形针图标或使用Advanced Data插件
正确方式3:分段处理
适用于超长文档(超过AI上下文限制)。
虽然现在AI的上下文窗口已经很长,但有些文档仍然可能超出限制。
处理方法:
- 将文档分成几个部分(每部分不超过AI限制)
- 逐段发送给AI
- 让AI总结每一部分的核心内容
- 最后让AI综合所有总结做整体分析
3.2 提问的黄金法则
给AI喂了文档之后,接下来就是提问环节。
很多人的问题是:提问太空泛,AI回答得太泛泛。
反面案例:
“帮我总结一下这篇文档”
这样的提问太笼统,AI给的回答往往是流水账式的摘要,没有重点。
正面案例:
“这是一份市场调研报告。请帮我:
- 提炼出3个核心发现
- 分析报告指出的主要市场趋势
- 找出报告中与竞品对比的关键数据
- 总结报告对未来市场的预测”
这样的提问具体明确,AI的回答也会更有价值。
提问公式:
角色 + 任务 + 具体要求
示例:
“你是一个专业的金融分析师。我这里有一份某公司的年报。请帮我:
- 分析公司的盈利能力(重点看毛利率、净利率变化)
- 评估公司的偿债能力
- 判断公司的发展趋势
- 指出需要注意的风险点”
3.3 追问的艺术
好的长文本分析往往需要多轮对话。
技巧1:从模糊到具体
第一轮先让AI给出一个overview,了解文档的整体框架。
第二轮再针对具体细节追问。
技巧2:让AI复述关键信息
可以这样问:
“关于XX这部分内容,请用更简单直白的语言解释一下”
或者:
“能否举个例子说明这个概念”
技巧3:让AI进行对比分析
如果有多篇相关文档,可以这样问:
“这份报告和上周那份报告相比,在XX问题上有什么不同的观点?”
四、实战场景:论文阅读
4.1 场景描述
作为学生或研究者,经常需要阅读大量学术论文。
4.2 使用技巧
第一步:快速判断论文价值
不要一上来就从头读到尾。先让AI帮你做初步筛选:
“这是一篇学术论文的摘要和目录。请帮我:
- 判断这篇论文的研究主题是什么
- 评估这篇论文与我研究方向的关联度(1-10分)
- 指出论文可能包含的关键结论”
第二步:理解论文结构
“请梳理这篇论文的结构,包括:
- 研究问题是什么
- 使用了什么方法
- 主要发现了什么
- 结论有什么意义”
第三步:深入分析某个章节
“关于论文的’实验设计’部分,请详细解释:
- 实验是如何设计的
- 控制了哪些变量
- 实验结果的可靠性如何”
第四步:提取可用的素材
“请从这篇论文中提取:
- 可以引用的核心观点(3-5个)
- 研究方法的亮点
- 可能用于我论文的数据或图表”
4.3 提示词模板
针对论文阅读,我常用的提示词模板:
plaintext
请作为一位专业的学术研究员,帮我分析这篇论文:
1. 【快速概览】用3句话概括这篇论文的核心内容
2. 【研究价值】这篇论文对我的研究(研究方向:XXX)有什么参考价值?
3. 【方法评估】这篇论文使用的研究方法有什么优缺点?
4. 【关键发现】论文最重要的3个发现是什么?
5. 【批判思考】这篇论文有什么局限性?结论是否可靠?
6. 【引用建议】如果我要引用这篇论文,应该重点引用哪些部分?
五、实战场景:合同审查
5.1 场景描述
职场人经常需要审查各种合同:劳动合同、采购合同、服务合同等。
5.2 使用技巧
第一步:整体了解
“请帮我审阅这份合同:
- 这是一份什么类型的合同
- 合同的主要条款有哪些
- 合同双方分别是谁”
第二步:风险识别
“请识别这份合同中的潜在风险点,重点关注:
- 付款条件和时间
- 违约责任条款
- 免责条款
- 争议解决方式”
第三步:关键条款解读
“请详细解释合同中的XX条款,用通俗易懂的语言说明其含义和影响”
第四步:修改建议
“基于以上分析,请提出你认为需要修改或补充的条款建议”
5.3 注意事项
重要提醒:AI可以帮助你理解合同,但不能替代专业法律意见!
对于重要合同,建议:
- 用AI做初步了解和分析
- 识别需要关注的重点
- 带着问题咨询专业律师
- 最终决策要依靠专业判断
六、实战场景:市场报告分析
6.1 场景描述
职场人经常需要阅读行业研究报告、市场分析报告等。
6.2 使用技巧
第一步:快速定位关键信息
“这是一份XX行业的市场研究报告。请帮我:
- 提炼出报告的5个核心观点
- 找出报告中引用的关键数据
- 识别报告对行业趋势的判断”
第二步:深度分析
“请详细分析报告中关于XX细分市场的内容,包括:
- 市场规模和增长率
- 主要竞争格局
- 增长驱动因素
- 潜在风险和挑战”
第三步:竞品对比
“报告中提到了哪些主要竞争者?请对比分析它们的优劣势”
第四步:提炼洞察
“基于报告内容,请给出:
- 对行业从业者的3条建议
- 对投资者的2个关键指标关注点
- 未来3年行业的发展预测”
6.3 提示词模板
plaintext
请作为一位资深的市场分析师,帮我深度解读这份市场报告:
## 整体框架
- 报告的核心研究问题是什么?
- 报告的时间范围和数据来源是什么?
## 市场洞察
- 当前市场规模和历史增长情况
- 市场增速的驱动因素有哪些
## 竞争分析
- 市场主要玩家有哪些
- 各玩家的市场份额和策略差异
- 竞争格局的变化趋势
## 趋势判断
- 报告中预测的行业趋势
- 影响行业的关键变量
- 潜在的机会和威胁
## 实用建议
- 对行业从业者的建议
- 对投资决策有价值的洞察
七、进阶技巧:复杂文档处理
7.1 多文档对比分析
当你需要对比多份相关文档时,可以这样操作:
步骤1:分别上传各文档
步骤2:让AI分别总结每份文档
步骤3:进行对比分析
提示词示例:
“我上传了三份关于XX行业的研究报告,请帮我:
- 对比三份报告的核心观点,找出共同点和分歧
- 分析三份报告的数据来源和可靠性
- 总结目前行业的主流观点和争议焦点
- 给出你的综合判断”
7.2 复杂文档拆解
对于结构复杂的大型文档(如书籍),可以采用分层处理法:
第一层:让AI梳理整体结构
“请梳理这份文档的整体框架,列出主要章节和各章节的主题”
第二层:分章节处理
对每个章节进行详细分析
第三层:综合理解
“基于对各章节的理解,请总结:
- 文档的核心理论/观点
- 各部分之间的逻辑关系
- 对你而言最有价值的3个知识点”
7.3 提取可复用内容
对于需要做知识管理的场景:
“请从这份文档中提取:
- 核心概念和定义
- 实用的方法论或框架
- 可以直接引用的金句
- 实用的案例和示例”
八、常见问题解答
Q1:AI处理长文档会遗漏重要信息吗?
有可能。尤其是当文档超出AI上下文限制时,需要分段处理。
建议:
- 采用分段处理,确保每个部分都被完整分析
- 最后让AI做整体回顾,检查是否有遗漏
- 重要细节可以单独提问确认
Q2:如何确保AI理解准确?
建议:
- 使用结构化的提问方式
- 让AI先复述自己的理解
- 对重要结论追问依据
Q3:AI的分析结论可靠吗?
AI的分析是辅助性的,不能完全依赖。
建议:
- 关键信息交叉验证
- 重要决策需要人工确认
- 保持批判性思维
Q4:不同AI工具效果差异大吗?
有差异。在不同场景下,各有优势:
- 中文内容:Kimi通常更好
- 深度分析:Claude通常更详细
- 综合场景:ChatGPT更全能
建议根据具体需求选择合适的工具。
九、写在最后
AI长文本处理是一个需要练习的技能。
今天分享的技巧,需要你在实际使用中不断练习和调整。
我的建议是:
- 从简单场景开始:先用短文档练手,熟悉基本操作
- 逐步挑战复杂任务:等熟练后再处理长文档和复杂分析
- 建立自己的提示词库:把好用的提问方式记录下来
- 保持批判性思维:AI是助手,最终判断权在你手里
掌握这些技巧后,你会发现:
- 阅读效率可以提升5-10倍
- 信息吸收更加系统化
- 从”读完”变成”读懂”
这才是AI真正的价值所在:不是替代你的思考,而是放大你的能力。
相关阅读推荐: