一、Manus AI是什么
最近科技圈都在讨论一个名字——Manus AI。
说实话,第一次看到这个名字的时候,我以为又是某个新出的ChatGPT套壳产品。但深入了解之后发现,这次还真不太一样。
Manus这个词来自拉丁语,意思是”手”。创始团队想表达的是:这个AI不仅仅是个会聊天的工具,而是真正能”动手做事”的智能助手。
那么问题来了:Manus AI到底能做什么?
简单来说,它是一个通用AI智能体(General AI Agent)。和传统AI助手只能回答问题不同,Manus能够接收复杂的多步骤任务,然后自主规划执行路径,异步完成工作,最后把结果交付给你。
举几个例子你就明白了:
- 你扔给它一份包含10份简历的压缩包,它能自动解压、逐个分析,生成一份排好序的候选人排名表
- 你让它分析某只股票,它会自己上网查数据、做分析图表、写投资报告
- 你需要一个旅行规划,它会综合你的预算、偏好、时间,自动生成详细的行程单
这听起来是不是有点像以前吹过的”AI智能体”的牛皮?但Manus的不同之处在于,它真的在执行,而且执行得相当不错。
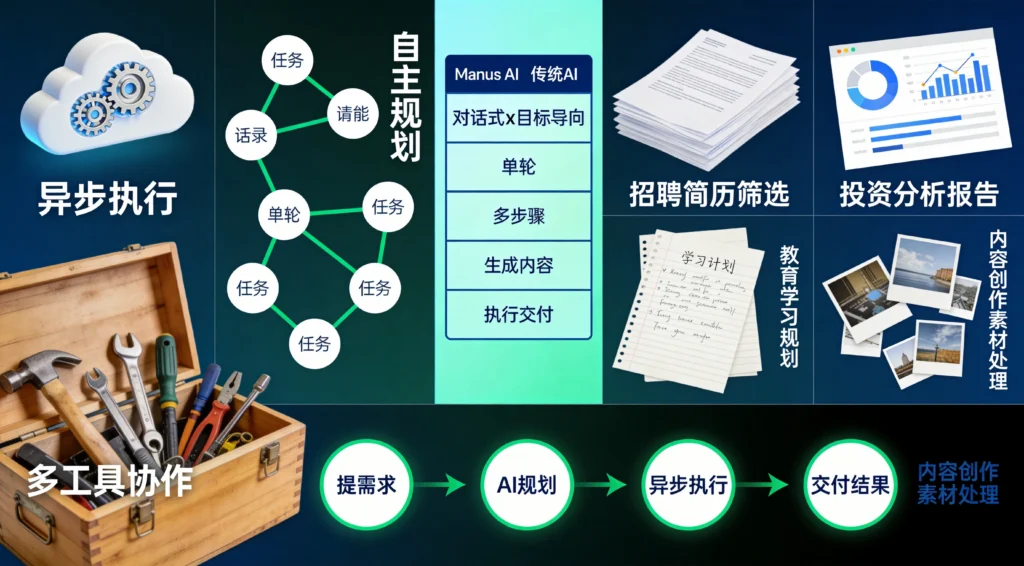
二、Manus的核心能力解析
2.1 异步执行:让AI自己干活
Manus最让我惊艳的功能是异步执行能力。
什么意思呢?传统的AI助手,你必须一直开着对话框,它才能工作。你关闭页面,AI就停止。
Manus打破了这一点。当你提交一个任务后,即使你关闭了浏览器,Manus也会继续在云端工作。等它完成后,会主动通知你。
这就好比你雇了一个助理,你可以把任务交代下去,然后去忙别的事情。助理会在任务完成后给你发消息汇报。
这个功能在实际工作中非常实用。比如你需要:
- 凌晨做一份市场报告
- 同时处理几十份文档
- 进行长时间的股票数据分析
这些场景下,异步执行能力就派上用场了。
2.2 自主规划:AI会自己想办法
传统AI的工作模式是:人类给指令,AI执行。
Manus的工作模式是:人类给目标,AI自己规划路径。
举个具体的例子。你对ChatGPT说:”帮我分析这家公司值不值得投资。”
ChatGPT会怎么回应?它可能会问你要公司名字、财务数据、行业情况等信息。如果你不提供,它就只能泛泛而谈。
但如果你对Manus说同样的话,它会:
- 自动上网搜索这家公司的公开信息
- 获取财务报告、新闻报道、行业数据
- 使用分析框架进行多维度评估
- 生成可视化图表和投资建议报告
整个过程不需要你一步步指导。Manus会根据目标自主规划执行步骤。
2.3 多工具协作
Manus内置了丰富的工具调用能力:
- 浏览器操作:自动上网搜索、访问网页、提取信息
- 文件处理:读取文档、解析数据、生成报告
- 代码执行:编写和运行代码进行数据分析
- 环境交互:在独立的云端环境中操作各种应用
这种多工具协作能力让Manus能够处理复杂的多步骤任务,而不仅仅是单轮对话。
三、实际应用场景
说了这么多技术概念,你可能还是觉得有点抽象。让我结合具体场景聊聊Manus的实际价值。
3.1 招聘场景:快速筛选简历
这是我身边HR朋友用得最多的场景。
传统的招聘流程是这样的:HR从招聘网站下载简历→逐个打开阅读→根据条件筛选→整理候选人信息→约面试
这个过程非常耗时。如果每天收到50份简历,光是初筛就要花掉大半天。
用Manus处理这个工作:
- 把所有简历打包发给Manus
- 告诉它筛选条件(如:3年以上经验、本科以上、Python技能)
- Manus自动解压、逐个分析、生成候选人排名表
我那个HR朋友说,用了Manus之后,初筛时间从原来的6小时缩短到了45分钟。而且筛选标准更加客观一致。
3.2 投资分析:个股研究报告
对于投资爱好者来说,Manus可以快速生成个股分析报告。
你需要做的:
- 告诉Manus分析某只股票
- 说明你的关注重点(如:盈利能力、行业地位、风险因素)
- Manus自动完成:数据收集→财务分析→行业对比→风险评估→报告生成
生成的报告包含:
- 公司基本情况
- 财务指标分析
- 行业地位评估
- 估值分析
- 风险提示
- 投资建议
注意:Manus的分析仅供参考,不构成投资建议。投资决策还是要靠自己判断。
3.3 教育场景:个性化学习方案
对于学生和自学者,Manus可以帮你制定学习计划。
比如你对它说:”我想用3个月时间学习机器学习,目标是能够独立完成项目。”
Manus会:
- 评估你的基础水平(通过问答了解)
- 分析机器学习的知识体系
- 根据你的时间安排制定学习计划
- 推荐学习资源和实践项目
- 定期跟进学习进度
这种个性化的学习规划,对自学者来说非常有价值。
3.4 内容创作:批量处理素材
自媒体创作者经常需要处理大量素材。
比如你要写一篇产品评测,需要:
- 收集产品的用户评价
- 分析竞品信息
- 整理产品参数
- 撰写评测大纲
Manus可以帮你完成前几步的数据收集和整理工作,你只需要专注在内容创作上。
四、Manus vs 传统AI助手:有什么区别
很多人会问:Manus和ChatGPT、Claude这些AI助手有什么本质区别?
我用一张表格来对比:
| 维度 | ChatGPT/Claude | Manus AI |
|---|---|---|
| 工作模式 | 对话式,问答交互 | 目标导向,异步执行 |
| 任务复杂度 | 单轮或简单多轮 | 复杂多步骤任务 |
| 执行能力 | 仅生成内容 | 自主规划+执行+交付 |
| 状态保持 | 仅在对话期间 | 可异步后台运行 |
| 工具调用 | 有限插件能力 | 完整的工具生态 |
| 适用场景 | 问答、写作、分析 | 端到端任务自动化 |
简单总结:传统AI助手是”军师”,给你出主意;Manus是”助理”,帮你干实事。
两者并不是替代关系,而是互补关系。日常问答用ChatGPT,复杂任务执行用Manus。
五、如何开始使用Manus
目前Manus处于逐步开放阶段,有几种方式可以体验:
5.1 官方体验通道
- 访问Manus官方网站
- 填写体验申请(通常需要等待排队)
- 通过后获得体验资格
由于目前需求量大,官方排队时间可能较长。
5.2 关注产品动态
Manus团队持续在社交媒体发布产品更新:
- Twitter/X:@maboroshi_ai
- 官方博客:定期发布功能更新和使用案例
5.3 替代方案探索
如果暂时无法体验Manus,可以关注一些类似定位的产品:
- OpenAI的Agent相关项目
- Anthropic的Claude相关能力
- 国内的Coze智能体平台
这些产品虽然功能上与Manus有所差异,但也在朝着类似方向发展。
六、写在最后
说实话,第一次体验Manus的时候,我有一种”未来已来”的感觉。
以前我们总说AI要改变工作方式,但很多时候AI只是改变了我们与机器交互的方式,本质工作还是人在做。
Manus让我看到了不一样的可能:当AI真正具备执行能力的时候,人类可以从重复性工作中解放出来,专注于真正需要创造力、判断力和人情味的事情。
当然,现在讨论AI取代人类还为时过早。但至少在可见的未来,”AI搭档”会成为越来越多人的工作标配。
如果你对AI智能体感兴趣,或者在工作中经常需要处理重复性任务,不妨关注一下Manus的发展。说不定,它就是你在找的那个”靠谱助理”。
相关阅读推荐: