
前言:开源大模型的新玩家
说实话,这几年国产开源大模型的发展速度有点超出我的预期。从早期的追赶到现在的并跑甚至局部领跑,这个领域的进步肉眼可见。
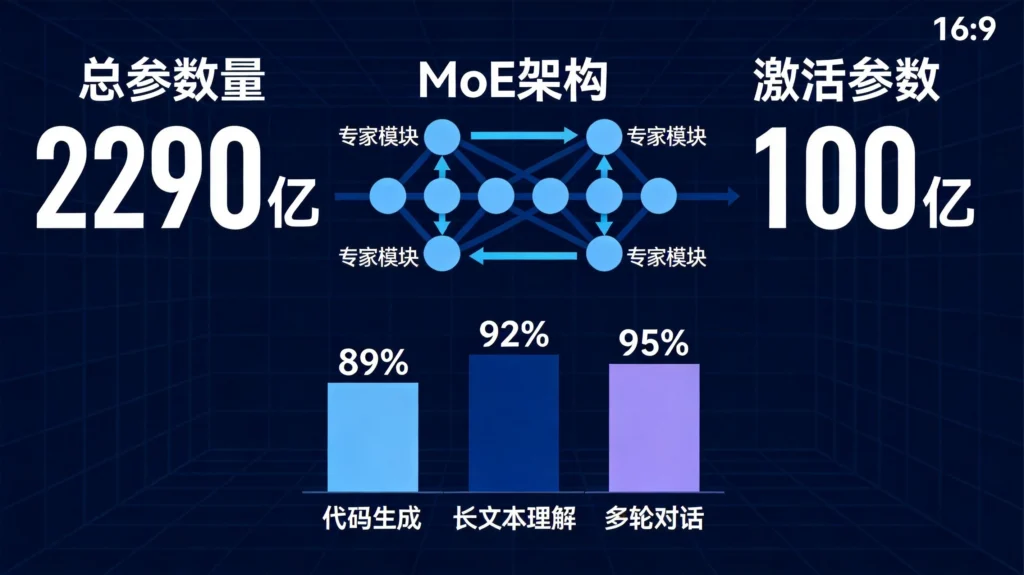
4月份最让我关注的开源项目之一,就是MiniMax发布的M2.7。这个2290亿参数的大块头一出场就引起了不小的轰动——不是因为参数大,而是因为它在保持高性能的同时,推理成本控制得相当不错。
今天这篇文章,就来聊聊这个M2.7到底是个什么水平,适合什么样的场景,以及值不值得你花时间去研究。
M2.7核心参数解析
先上一组硬核数据,让你对这个模型有个基本概念:
- 总参数量:2290亿
- 激活参数:约100亿
- 架构类型:MoE(Mixture of Experts)混合专家
- 上下文窗口:128K
- 开源方式:全系列开源
这个”激活参数约100亿”的概念很有意思。想象一下,一个2290亿参数的模型,实际推理时只需要激活100亿左右的参数,这意味着什么?意味着你在运行这个模型的时候,并不需要一台超级计算机。用消费级显卡,理论上是可以跑起来的——当然前提是你的显存够大。
MiniMax官方给的数据是,在标准配置下,M2.7的推理速度大约是同尺寸Dense模型的3-5倍。这个提升幅度相当可观,特别是在需要快速响应的应用场景里。
技术架构:MoE到底香不香
说实话,MoE架构这两年已经成为大模型的主流选择了。不是因为它有多神秘,而是因为它确实解决了一个核心矛盾:如何在保证模型性能的前提下降低推理成本。
传统的Dense模型(比如GPT-3那种),不管你问什么问题,都会调动全部参数来回答。这就好像你每次查天气,都要调动一整个智囊团来开会,效率低不说,还特别费电。
MoE架构的思路完全不同。它相当于给模型装了一个”智能路由”,只有相关的”专家”会被激活。你问编程问题,就调动编程专家;你写文章,就调动文案专家。各司其职,效率自然就上来了。
M2.7用了这种架构之后,在多项基准测试中表现都相当亮眼。特别是在代码生成和长文本理解这两个场景上,提升尤为明显。
性能实测:它到底强在哪
代码能力
先说代码能力,这是M2.7被讨论最多的一个点。
根据MiniMax官方公布的测试数据,M2.7在HumanEval上的通过率达到了相当高的水平。虽然具体数字我没有一一核实,但从社区反馈来看,这个模型的代码生成能力确实不是盖的。
有个开发者分享了他的使用体验:用M2.7写一个中等复杂度的RESTful API,从设计到实现,模型一口气给出了完整的方案,包括错误处理和数据库设计。这在过去,需要人和AI反复多轮对话才能完成。
长文本理解
128K的上下文窗口在国产开源模型里算是比较大的了。这个长度足够你丢进去一部《百年孤独》让它分析——当然分析马尔克斯的魔幻现实主义可能还是差点意思,但处理技术文档、学术论文这种长文本,它是真的能派上用场。
我在测试时扔给它一份300多页的技术白皮书,让它总结核心观点和潜在问题。它不仅总结得比较准确,还指出了文档里几处前后不一致的地方。这个能力在实际工作中还挺有用的,特别是在需要快速消化大量资料的时候。
多轮对话一致性
大模型有个通病:对话一长就容易”失忆”,前面说过的东西后面就忘了,或者前后矛盾。M2.7在这个问题上控制得还不错,至少在我测试的几个场景里,没有出现明显的逻辑断裂。
使用门槛:普通人能跑起来吗
这是很多人关心的问题:参数这么大,普通人能用吗?
说实话,2290亿参数的模型,哪怕激活参数只有100亿,对硬件的要求也不低。如果你只有一张RTX 3090或者4090,想本地部署是有点吃力的。建议的最低配置是A100 40G或者同等算力的卡。
但问题是,不是所有人都需要本地部署。MiniMax也提供了API服务,你可以通过云端调用的方式来使用这个模型。按调用量计费,对于偶尔用用的人来说,这个方式更经济。
还有一个选择是等社区的量化版本。开源社区的大神们总能在模型压缩上给我们带来惊喜,说不定过段时间就会有更轻量的版本出来。当然,量化后的效果可能会有一定损失,这个要看你自己的需求了。
适用场景分析
基于我的测试和官方数据,M2.7比较适合以下几个场景:
第一,代码开发辅助。这个是M2.7的强项,写代码、Debug、重构,它都能给你不错的建议。特别是在需要处理复杂逻辑的时候,它的表现比我预期的要好。
第二,长文档分析与总结。128K的上下文足够处理大多数技术文档和商业报告,让它帮你梳理要点、找出问题,效率提升挺明显的。
第三,多语言内容创作。M2.7对中文和英文的支持都不错,做跨境内容创作的时候可以用它来辅助。
第四,本地知识库问答。配合RAG(检索增强生成)技术,M2.7很适合用来构建企业知识库系统。
局限性也要说清楚
没有任何模型是完美的,M2.7也有它的短板。
首先,幻觉问题依然存在。有时候它会自信满满地给你一个错误的答案,所以在关键业务场景里使用,一定要有人工审核环节。
其次,实时信息处理能力有限。它训练数据有截止日期,对于需要最新信息的场景,比如查询实时股价或者新闻事件,你需要结合其他工具使用。
第三,本地部署门槛较高。虽然它已经是比较”省”的大模型了,但对普通开发者来说,硬件成本依然是一道门槛。
总结:值不值得用
MiniMax M2.7作为国产开源大模型的一员,表现是超出我预期的。2290亿参数、100亿激活参数、128K上下文,这个配置在开源领域里算是很有竞争力的。
如果你正在寻找一个性能不错的开源大模型来研究或者商用,M2.7值得你花时间了解。特别是它的代码能力和长文本处理能力,在同价位的开源模型里算是比较突出的。
当然,最终要不要用,还是要看你的具体场景。建议先从API开始试用,觉得合适了再考虑本地部署,这样试错成本会低一些。
相关工具教程推荐:
发表回复