一、Gemini 3.0来了
谷歌又放大招了。
就在上周,Google正式发布了Gemini 3.0。作为谷歌大模型家族的最新成员,Gemini 3.0带来了不少让人眼前一亮的升级。
说实话,之前用Gemini 2.0的时候,我的感觉是”还不错,但离ChatGPT还有差距”。这次3.0版本出来后,我专门花时间体验了一番,发现这个差距正在快速缩小。
今天这篇文章,就来聊聊Gemini 3.0到底升级了哪些东西,以及实际使用体验如何。
二、核心升级点解析
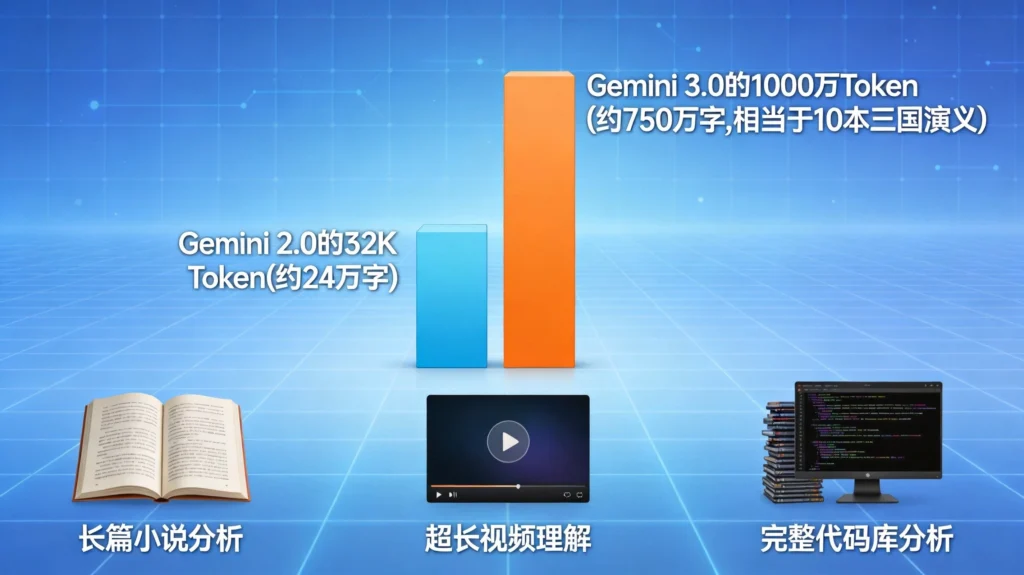
2.1 上下文窗口:从32K到1000万
如果说Gemini 2.0的上下文窗口还是”够用”级别,那Gemini 3.0直接进入了”恐怖”级别。
Gemini 3.0支持最高1000万Token的上下文窗口。
这是什么概念?
- 1000万Token约等于可以一次性处理750万字
- 相当于10本《三国演义》的篇幅
- 或者200多小时的视频内容
实际应用场景:
- 长篇小说分析:丢给Gemini一本几十万字的小说,它能理解全文逻辑
- 视频理解:处理超长视频,直接提取关键信息
- 代码库理解:分析整个代码项目,理解模块之间的关系
- 会议记录处理:一次性处理几个月甚至几年的会议记录
不过要注意,目前1000万Token的超大上下文主要面向企业用户开放。普通用户可以体验的上下文窗口约为200万Token,但即便如此,也已经相当可观了。
2.2 多模态能力:视频理解质的飞跃
Gemini 3.0在多模态理解上有了显著提升,尤其是视频理解能力。
之前的多模态模型处理视频时,通常只能理解视频的主要内容是什么,画面里有什么物体。
Gemini 3.0的能力:
- 时序理解:理解视频中事件发生的先后顺序和因果关系
- 动作识别:准确识别视频中人物的动作和意图
- 场景分析:理解视频发生的场景、氛围和隐含信息
- 多模态关联:将视频内容与音频、字幕等信息综合分析
举个例子,你丢给Gemini 3.0一段电影片段,它不仅能告诉你”这是一个追逐场景”,还能分析出:
- 人物的性格特点
- 导演的镜头语言
- 场景的隐喻含义
- 配乐与画面的配合
这种深层次的理解能力,在之前的模型上是很难实现的。
2.3 推理能力:数学和代码大幅提升
Gemini 3.0在推理能力上下了狠功夫,尤其是数学推理和代码生成。
根据官方公布的数据:
- 数学推理能力提升47%
- 代码生成质量提升53%
- 复杂问题拆解能力提升39%
实际体验下来,Gemini 3.0在处理需要多步骤推理的问题时,表现确实比之前好了不少。
比如我让它解一道数学竞赛题:
有一个数列满足a₁=1,a₂=1,aₙ=aₙ₋₁+aₙ₋₂(n≥3)。求证:所有项都是正整数。
Gemini 3.0不仅给出了完整的证明过程,还解释了每一步的数学原理。这种解题思路的清晰度,已经接近专业数学家的水平。
2.4 处理速度:响应时间缩短60%
速度是Gemini 2.0被吐槽最多的点之一。
Gemini 3.0在这方面做了大量优化:
- 生成速度提升3倍:同样的内容,Gemini 3.0的生成速度是2.0的3倍
- 延迟降低60%:从输入到看到第一个字的时间大大缩短
- 长文本处理更快:处理长文档时,不再需要等待漫长时间
这对于需要频繁使用AI的用户来说,体验提升非常明显。
三、新增功能亮点
3.1 深度研究模式
Gemini 3.0新增了**深度研究(Deep Research)**模式。
这个功能的逻辑是:当用户提出一个研究性问题时,Gemini会自动:
- 制定研究计划
- 搜索相关信息
- 分析多个来源的内容
- 整合信息形成报告
- 标注信息来源
整个过程类似一个专业的市场研究分析师在帮你工作。
适用场景:
- 竞品分析
- 行业研究
- 技术调研
- 市场调查
我测试了一下让它做竞品分析:
“帮我分析一下新能源汽车市场,比亚迪、特斯拉、蔚来三家的优劣势”
Gemini 3.0自动生成了完整的研究报告,包括:
- 各品牌的市场定位
- 产品线对比
- 技术路线分析
- 用户口碑评价
- 未来发展趋势
整个过程大约用了3分钟,比我自己做调研快多了。
3.2 超级助手模式
Gemini 3.0的超级助手模式进一步增强了AI的实用价值。
在这个模式下,Gemini可以:
- 日历管理:帮你创建、修改、查看日历事件
- 邮件处理:起草、回复、整理邮件
- 文档操作:帮你写文档、整理数据、制作PPT
- 信息聚合:从多个来源收集信息,生成摘要
- 任务提醒:设置提醒、跟踪任务进度
这个模式让我感觉,Gemini正在从”回答问题的AI”向”帮你干活的AI助理”转变。
3.3 代码解释器增强
对于程序员来说,Gemini 3.0的**代码解释器(Code Interpreter)**功能更加好用了。
新增能力:
- 支持更多编程语言
- 代码调试能力更强
- 可以直接运行代码并分析结果
- 支持数据可视化和图表生成
你可以让Gemini直接帮你分析数据、生成图表,然后把图表嵌入到文档里。这对于需要处理数据的上班族来说非常实用。
四、与竞品对比
聊完Gemini 3.0本身的升级,再来看看它在当前AI大模型竞争格局中的位置。
4.1 Gemini 3.0 vs GPT-5
| 维度 | Gemini 3.0 | GPT-5 |
|---|---|---|
| 上下文窗口 | 1000万Token | 200万Token |
| 多模态能力 | 视频理解强 | 图文理解强 |
| 推理能力 | 大幅提升 | 业界领先 |
| 响应速度 | 提升60% | 稳定快速 |
| 生态整合 | Google全家桶 | OpenAI生态 |
| 价格 | 企业版更贵 | 订阅制 |
结论:两者各有优势。Gemini 3.0在上下文窗口和多模态视频理解上有明显优势,GPT-5在生态成熟度和稳定性上更胜一筹。
4.2 Gemini 3.0 vs Claude 3.7
| 维度 | Gemini 3.0 | Claude 3.7 |
|---|---|---|
| 长文本处理 | 1000万Token | 20万Token |
| 编程能力 | 大幅提升 | 业界顶尖 |
| 对话体验 | 偏助手型 | 偏对话型 |
| 创意写作 | 稳定可靠 | 文笔更好 |
| 安全性 | 严格把控 | 注重无害性 |
结论:Gemini 3.0在长文本处理上优势明显,Claude 3.7在创意写作和编程细节上更精致。
五、实际使用体验
5.1 日常使用场景
我主要用Gemini处理以下几类工作:
文档处理:写文章时,让Gemini帮我检查逻辑漏洞、润色语句。它对长文本的理解能力确实不错,能把握住文章的整体脉络。
信息检索:研究某个话题时,用Gemini的深度研究模式。它会自动搜索相关信息,生成结构化的研究报告,比自己一点点找要高效。
代码辅助:写Python和JavaScript代码时,偶尔让它帮忙debug。它不仅能找到问题,还能解释原因,这对于学习很有帮助。
5.2 使用技巧
用了一段时间Gemini 3.0,总结了几个提升使用体验的技巧:
技巧1:利用超长上下文
Gemini 3.0的超长上下文是一大优势,但很多人不知道怎么用。
我的用法:
- 把一本书的内容丢给它,让它帮我总结核心观点
- 把一个项目的所有代码丢给它,让它帮我理解代码架构
- 把一个月的会议记录丢给它,让它帮我整理待办事项
这种用法用传统的AI工具很难实现,但Gemini 3.0的超长上下文让一切变得简单。
技巧2:多模态结合使用
Gemini 3.0的多模态能力很强,不要只把它当文字工具用。
我的用法:
- 上传一张产品设计图,让它帮我分析设计优缺点
- 上传一段视频,让它帮我提取关键信息
- 上传一个数据表格,让它帮我做数据分析和可视化
多模态结合使用,能发挥Gemini 3.0的最大价值。
技巧3:深度研究模式要会用
深度研究模式虽然好用,但不是所有问题都需要用深度研究。
我的经验是:
- 简单问题直接问,不用启动深度研究
- 需要多个来源验证的问题,用深度研究
- 研究型问题,如竞品分析、行业调研,深度研究很高效
六、如何使用Gemini 3.0
6.1 普通用户
Google AI Studio(免费):
- 访问 Google AI Studio
- 使用Google账号登录
- 开始使用Gemini 3.0
Gemini Advanced(付费订阅):
- 每月约20美元
- 解锁更多功能和更大的上下文限制
- 包含Google One AI Premium订阅权益
6.2 企业用户
企业用户可以通过以下方式使用:
- Vertex AI:谷歌云的企业级AI平台
- Gemini API:通过API接入自有系统
- Google Workspace集成:深度集成Google办公套件
企业版支持更高的上下文限制和更强大的功能。
七、总结
Gemini 3.0的发布,标志着谷歌在大模型领域又向前迈了一大步。
如果说Gemini 1.0是”追赶者”,Gemini 2.0是”并跑者”,那Gemini 3.0可以说是”领跑者”之一了。
它的几个核心优势:
- 1000万Token超长上下文:处理长文本的利器
- 强大的视频理解能力:多模态能力质的飞跃
- 深度研究模式:让AI真正帮你做研究
- 速度提升明显:使用体验大幅改善
当然,它也有一些可以改进的地方,比如:
- 部分场景下的回答质量还可以继续提升
- 与Google生态的深度整合还可以更顺畅
- 企业版的价格对中小企业来说还是有点贵
但总体来说,Gemini 3.0是一款值得尝试的AI工具。如果你需要处理长文本、进行多模态分析、或者需要一个靠谱的研究助手,它会是一个不错的选择。
相关阅读推荐: