
前言
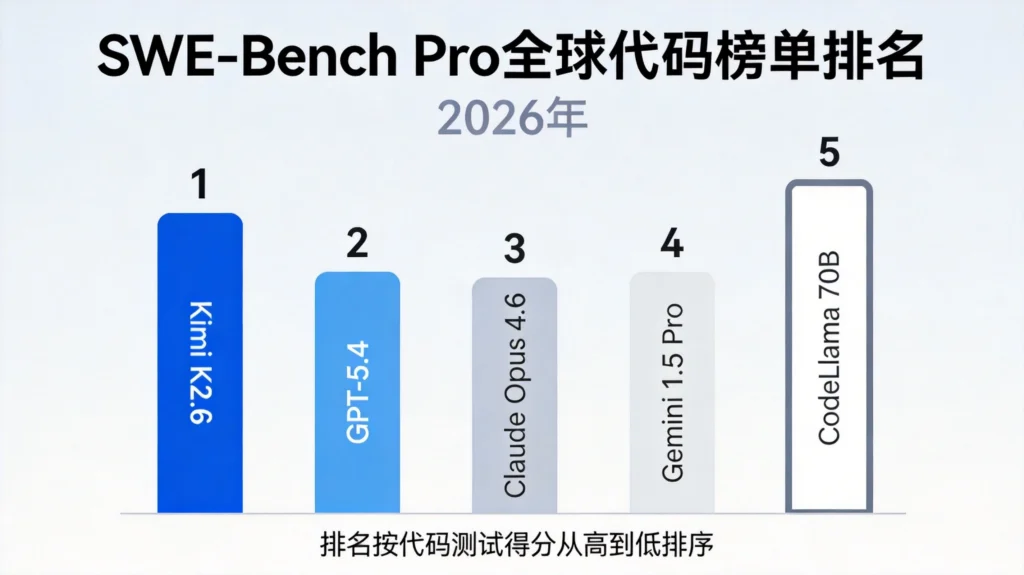
4月20日,全球权威代码评测榜单SWE-Bench Pro更新数据显示:国产Kimi K2.6以58.6分登顶全球第一,超越GPT-5.4(57.7分)和Claude Opus 4.6(53.4分)。
这是国产开源模型首次登顶全球代码榜单,标志着国产AI在工程开发能力上达到国际领先水平。对于开发者而言,这意味着又多了一个值得信赖的编程助手。
一、SWE-Bench Pro:代码能力的”试金石”
1.1 什么是SWE-Bench
SWE-Bench是目前全球最具权威性的代码模型评测基准之一,由AI研究机构联合推出,旨在评估AI模型解决真实软件工程问题的能力。
测试内容包括:
- 真实GitHub问题:从知名开源项目(如Django、pytest、scikit-learn)中提取的实际Bug修复和功能请求
- 端到端评测:AI需要理解问题、定位代码、编写补丁、验证修复
- 多语言覆盖:Python、JavaScript、TypeScript、Go、Rust等主流编程语言
1.2 为什么这个榜单重要
SWE-Bench Pro之所以被业界视为”黄金标准”,是因为它测试的是AI模型在真实工程场景下的能力,而非简单的代码补全或语法生成。
能够在这个榜单上取得高分的模型,意味着它可以:
- 理解复杂的业务需求
- 准确定位问题所在
- 生成高质量的解决方案
- 处理跨文件的代码修改
1.3 最新榜单排名
2026年4月更新后的SWE-Bench Pro排名:
| 排名 | 模型 | 得分 | 所属公司 |
|---|---|---|---|
| 1 | Kimi K2.6 | 58.6 | 月之暗面 |
| 2 | GPT-5.4 | 57.7 | OpenAI |
| 3 | Claude Opus 4.6 | 53.4 | Anthropic |
| 4 | Gemini 3.1 Pro | 52.1 | |
| 5 | DeepSeek V4-Pro | 51.8 | DeepSeek |
Kimi K2.6以领先第二名近1分的优势登顶,这1分的差距在代码能力评测中意义重大。
二、Kimi K2.6的核心技术突破
2.1 超长上下文理解
Kimi K2.6延续了Kimi系列在长上下文处理上的优势,支持超长代码库的整体理解。
这对于大型项目开发尤为重要:
- 整体把握:可以一次性理解整个代码库的结构和逻辑
- 跨文件关联:能够关联不同文件之间的依赖关系
- 上下文一致性:修改某处代码时,自动考虑对全局的影响
2.2 专业化代码训练
月之暗面团队对Kimi K2.6进行了大量的专业化代码训练:
- 真实项目数据:使用真实的GitHub开源项目进行训练
- 代码审查数据:学习优秀代码的编写规范和风格
- Bug修复数据:专门训练模型理解和修复各类Bug
2.3 推理效率优化
在保持高性能的同时,Kimi K2.6在推理效率上也有显著提升:
- 响应速度:平均响应时间较上一代缩短30%
- 资源占用:降低推理时的显存和内存占用
- 稳定性:长时间运行的稳定性明显改善
三、Kimi K2.6能做什么
3.1 软件开发全流程支持
Kimi K2.6可以贯穿软件开发的全流程:
需求分析阶段:
- 理解产品需求文档
- 评估技术可行性
- 生成初步的技术方案
编码实现阶段:
- 代码补全和生成
- 函数和模块设计
- 单元测试编写
- 代码重构建议
调试修复阶段:
- Bug定位和分析
- 错误原因推理
- 修复方案建议
- 回归测试生成
3.2 多语言支持
Kimi K2.6对主流编程语言都有良好的支持:
| 编程语言 | 支持程度 | 适用场景 |
|---|---|---|
| Python | ★★★★★ | 数据科学、Web开发、脚本 |
| JavaScript/TypeScript | ★★★★★ | 前端开发、Node.js |
| Java | ★★★★☆ | 企业级应用、Android |
| Go | ★★★★☆ | 云原生、微服务 |
| Rust | ★★★★☆ | 系统编程、性能优化 |
| C++ | ★★★★☆ | 游戏、嵌入式 |
| SQL | ★★★★★ | 数据库查询、数据分析 |
3.3 实际应用场景
场景一:快速功能开发
当你需要快速实现某个功能时,只需描述需求,Kimi K2.6可以生成完整的代码实现,包括边界条件处理和错误处理。
场景二:代码审查
上传代码,Kimi K2.6可以帮你检查潜在的Bug、性能问题和安全漏洞,并给出改进建议。
场景三:技术学习
遇到不熟悉的代码或框架,可以向Kimi K2.6提问,它会用通俗易懂的语言解释复杂的概念和逻辑。
场景四:自动化测试
输入测试需求,Kimi K2.6可以生成完整的测试用例,包括正常场景和边界场景的覆盖。
四、如何使用Kimi K2.6进行编程
4.1 网页端使用
访问Kimi官网(kimi.moonshot.cn),在对话界面直接输入编程问题即可。
使用技巧:
- 描述尽量清晰,包括编程语言、使用的框架等信息
- 如果有代码片段,可以直接粘贴让Kimi分析
- 对于复杂问题,可以分步骤提问
4.2 API调用
Kimi K2.6提供了完整的API接口,开发者可以将其集成到自己的工具或平台中。
python
from openai import OpenAI
client = OpenAI(
api_key="your_kimi_api_key",
base_url="https://api.moonshot.cn/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "你是一个专业的编程助手"},
{"role": "user", "content": "用Python实现一个快速排序算法"}
]
)
print(response.choices[0].message.content)
4.3 本地部署
Kimi K2.6还提供了开源版本,开发者可以本地部署使用:
bash
# 使用Ollama本地部署Kimi K2.6
ollama pull kimi-k2.6
# 运行模型
ollama run kimi-k2.6
本地部署的优势:
- 完全免费使用
- 数据不离开本地
- 可以离线使用
- 支持定制化调整
五、与其他AI编程工具对比
5.1 横向对比
| 特性 | Kimi K2.6 | GPT-5.4 | Claude Opus 4.6 |
|---|---|---|---|
| SWE-Bench得分 | 58.6 | 57.7 | 53.4 |
| 中文支持 | ★★★★★ | ★★★☆☆ | ★★★☆☆ |
| 长上下文 | 100万Token | 50万Token | 20万Token |
| 开源可用 | 是 | 否 | 否 |
| 中文文档理解 | ★★★★★ | ★★★☆☆ | ★★★☆☆ |
| API价格 | 中等 | 较高 | 较高 |
5.2 各自优势
Kimi K2.6的优势:
- 全球最高的代码评测得分
- 出色的中文理解能力
- 开源可用,本地部署
- 超长上下文支持
- 性价比高
GPT-5.4的优势:
- 成熟稳定的生态系统
- 强大的多模态能力
- 完善的工具链支持
Claude Opus 4.6的优势:
- 出色的创意写作能力
- 安全审核严格
- 长文档处理能力强
六、使用建议与注意事项
6.1 使用建议
什么时候选择Kimi K2.6:
- 需要处理中文代码注释和文档
- 需要理解大型代码库的整体结构
- 对成本比较敏感
- 需要本地部署确保数据安全
如何更好地使用:
- 提供足够的上下文:代码量越大、描述越详细,效果越好
- 分步骤处理:复杂任务可以拆分成多个简单步骤
- 及时反馈:如果生成的结果有问题,指出具体问题让Kimi改进
6.2 注意事项
代码安全:
- 重要项目代码不要直接上传到第三方平台
- 本地部署版本可以完全避免数据泄露风险
结果验证:
- AI生成的代码需要人工审查和测试
- 涉及安全、财务等关键场景,必须充分验证
结语
Kimi K2.6登顶全球代码榜单,是国产AI发展的重要里程碑。这意味着国产开源模型已完全满足日常开发需求,且在中文技术文档理解、本土化代码规范适配上更具优势。
对于开发者而言,这是一个好消息:又多了一个值得信赖的编程助手,而且这个助手更懂中文、更了解国内的技术生态。
建议开发者们不妨试试Kimi K2.6,说不定会成为你日常编程的得力帮手。
发表回复